Bebop, my 83lb, 33 inch tall, Greyhound, loves three things: running fast, following me around the house, and treats. Whether it’s a chew treat, pizza out of a child’s hand who strayed too far from a party, or a small tray of cat food, he has a nose for what he likes and the athleticism to give him a fair shot at getting it. I’ve watched him eat for years, so it was upsetting to realize I don’t know what his favorite snack is, and can’t easily ask him.
Fortunately for Bebop’s palate, the Bradley-Terry model gives us a way to figure out a “strength” of treat from pairwise comparisons.
The model assigns each competitor (or treat) (i) a positive strength score pi.
Given two competitors i and j, the probability that i beats j is:
Pr(i > j) = pi/(pi + pj)
Equivalently, if we write each strength as an exponential score,
pi = eβi
then the same probability can be written as:
Pr (i > j) = eβi/(eβi + eβj)
So the model is saying: the difference between two competitors’ latent strengths determines the log-odds that one beats the other.
The Elo rating system used in chess is closely related. If Ri and Rj are Elo ratings, then:
Pr (i > j) = (10Ri/400)/(10Ri/400 + 10Rj/400)
However, modern Elo ratings are calculated incrementally to avoid expensive recompute cycles and allow scores to be updated after each match. After the game, (A)’s rating is updated by comparing the actual result to the expected result:
RA′ = RA + K(SA − EA)
where SA is the actual score: (1) for a win, (0.5) for a draw, and (0) for a loss. The constant K controls how much ratings move after each game.
So if a player wins a game they were expected to win, their rating only moves slightly. If they win a game they were expected to lose, their rating moves a lot. In this sense, Elo can be thought of as an online version of the Bradley-Terry idea: after each result, move the ratings in the direction of the prediction error. Elo makes sense for systems like chess because games arrive continuously and ratings need to update immediately. In this experiment, the dataset is small enough that we can simply fit the Bradley-Terry model directly after collecting the trials.
You might also recognize a related model from The Social Network movie, where global ranking from pairwise comparisons powered FaceSmash, an early social media experiment by Mark Zuckerberg.1 A third application is Chatbot Arena, which uses Bradley-Terry style rankings for model performance.2 Bradley-Terry is the solution you reach for when you want a global ranking but only have head-to-head comparisons.
Experiment
For the experiment, the setup is straightforward: we can take a set of treats, label them, and run a series of pairwise comparisons to discover which treat is best! Prior to the experiment, I trained a “choice” command. The same time every day, around 11pm, I go to the kitchen, select two different treats, say the word “choice”, and present the treats in either hand, allowing Bebop to only take one, with the other going back into the bag. By the time the experiment started, Bebop was used to the routine and sniffing both treats before taking one.

For the selection of treats, I used a combination of treats we have a history with, like Greenies, and searched Amazon for a variety of treats in different formats. Each of these treats is a slightly different size, but I decided to ignore the differences for the sake of simplicity. This could introduce size bias in the results, however, the experiment is run about 2 hours after dinner so he should be full, and makes the results consistent with how I will give him treats post-experiment. In other words, I’m not interested in an experiment that requires me to cut and weigh dog treats.
The treats selected are as follows:
- Treat A is MON2SUN, duck + rawhide. Amazon link
- Treat B is Greenies, large-size. Amazon link
- Treat C is Pork Chomps, the red ones. Amazon link
- Treat D is MON2SUN, chicken + rawhide. Amazon link
- Treat E is Pur Luv Chicken, dehydrated chicken. Amazon link
Data
For the pairings, I created a daily schedule with two head to head comparisons. Full source on github
C/B :: B
E/B :: EIn this example, we have two head to head match-ups, which is one day of trials. The first has Treat C in the left hand, Treat B in the right, and the winner is B. For the second, E is left hand, B is right, and the winner is E. To estimate how settled the result was, I ran a bootstrap experiment: repeatedly resampling the trials, fitting Bradley-Terry models to those samples, and recording how often each treat came out on top. Github source code
About halfway through the experiment, I realized that treats C & B, the “Pork Chomps” and Greenies, were reliably losing.
Because these were out of the running, I marked any planned trial with C or B with X to indicate that trial was skipped, and added more A/D/E trials to improve power.
Results
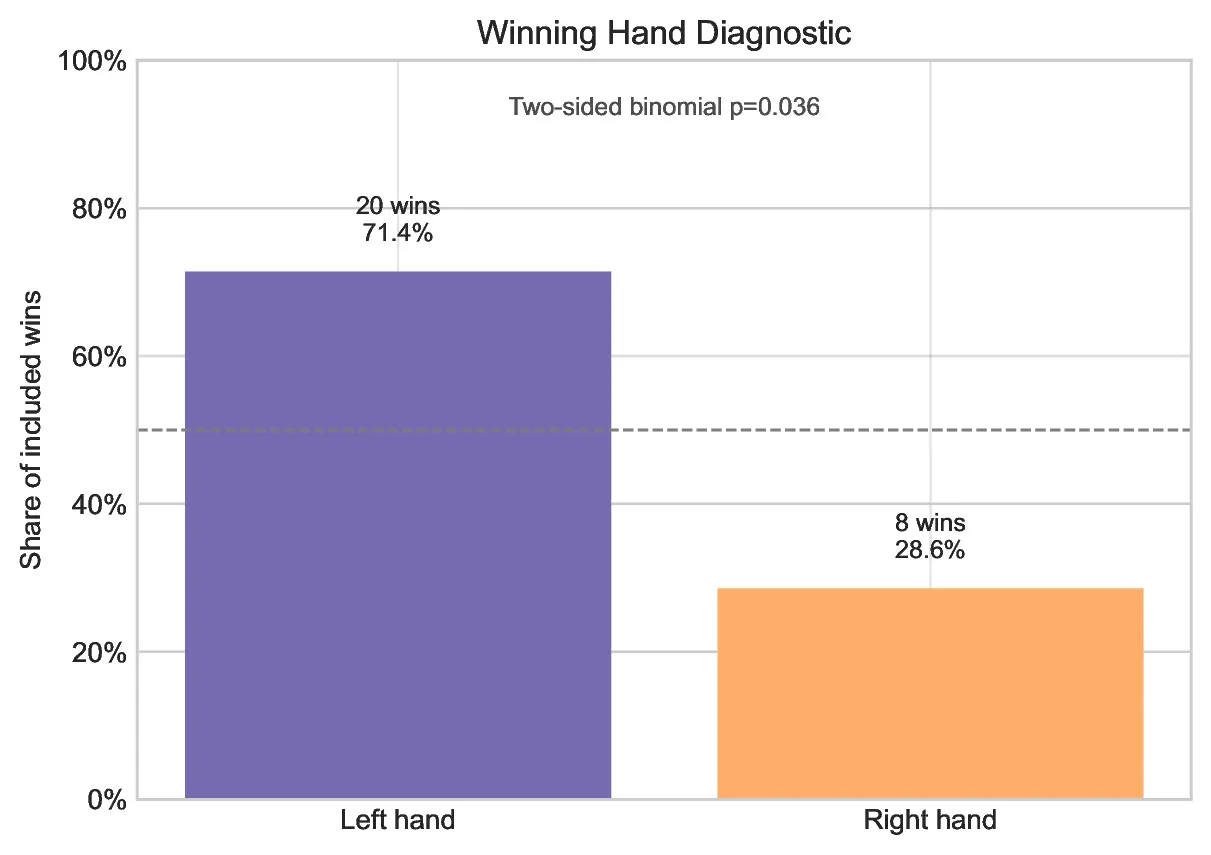
In the identical-treat trials, Bebop consistently chose the treat presented on his right side, which is my left hand. That does not prove he is “right-pawed,” because I measured side selection rather than paw use, but it does show a measurable right-side bias in this setup. One possible explanation is my non-symmetrical kitchen setup, with the left side being closer to a window fan which was sometimes on during the trial, but not controlled for.
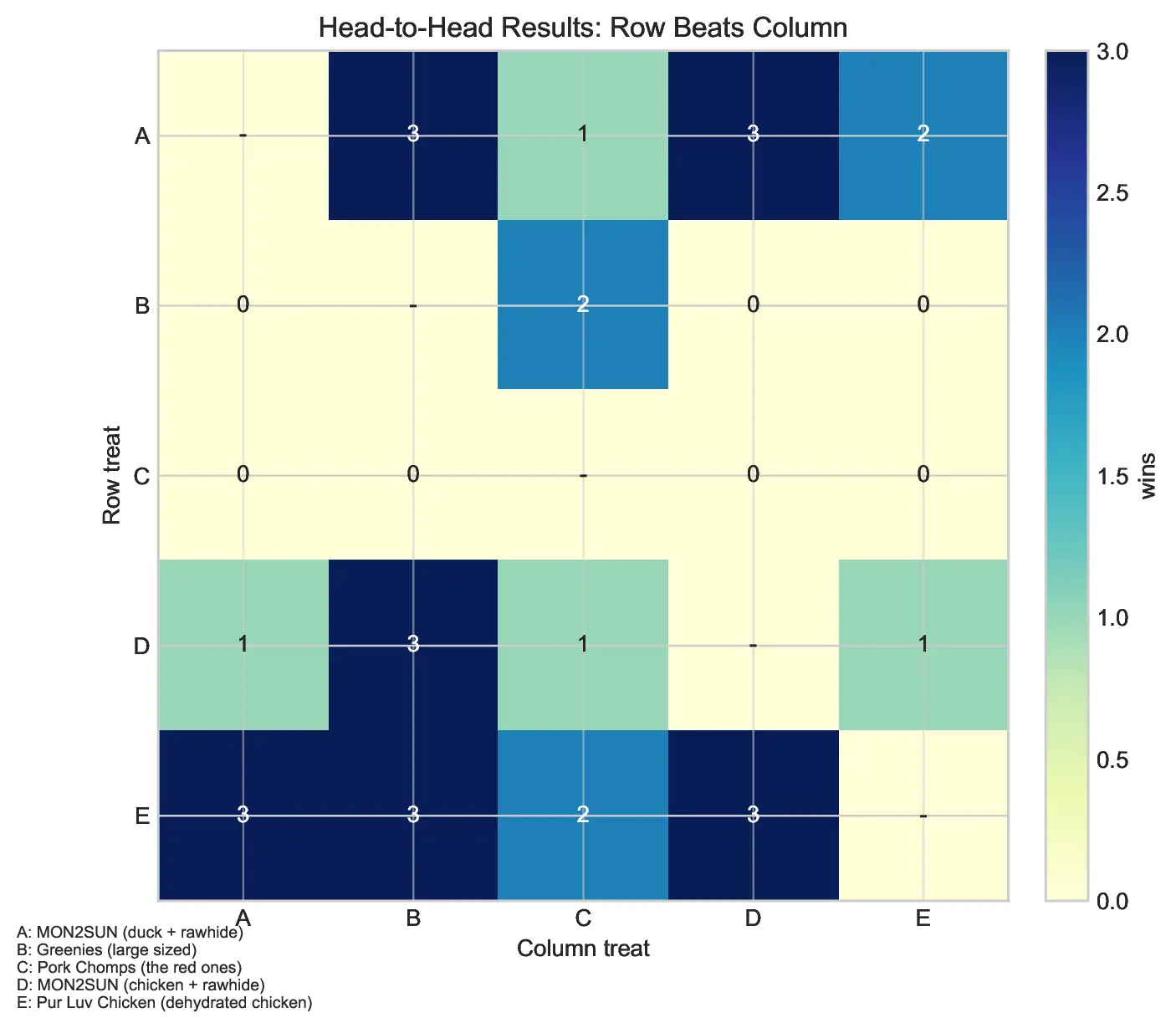
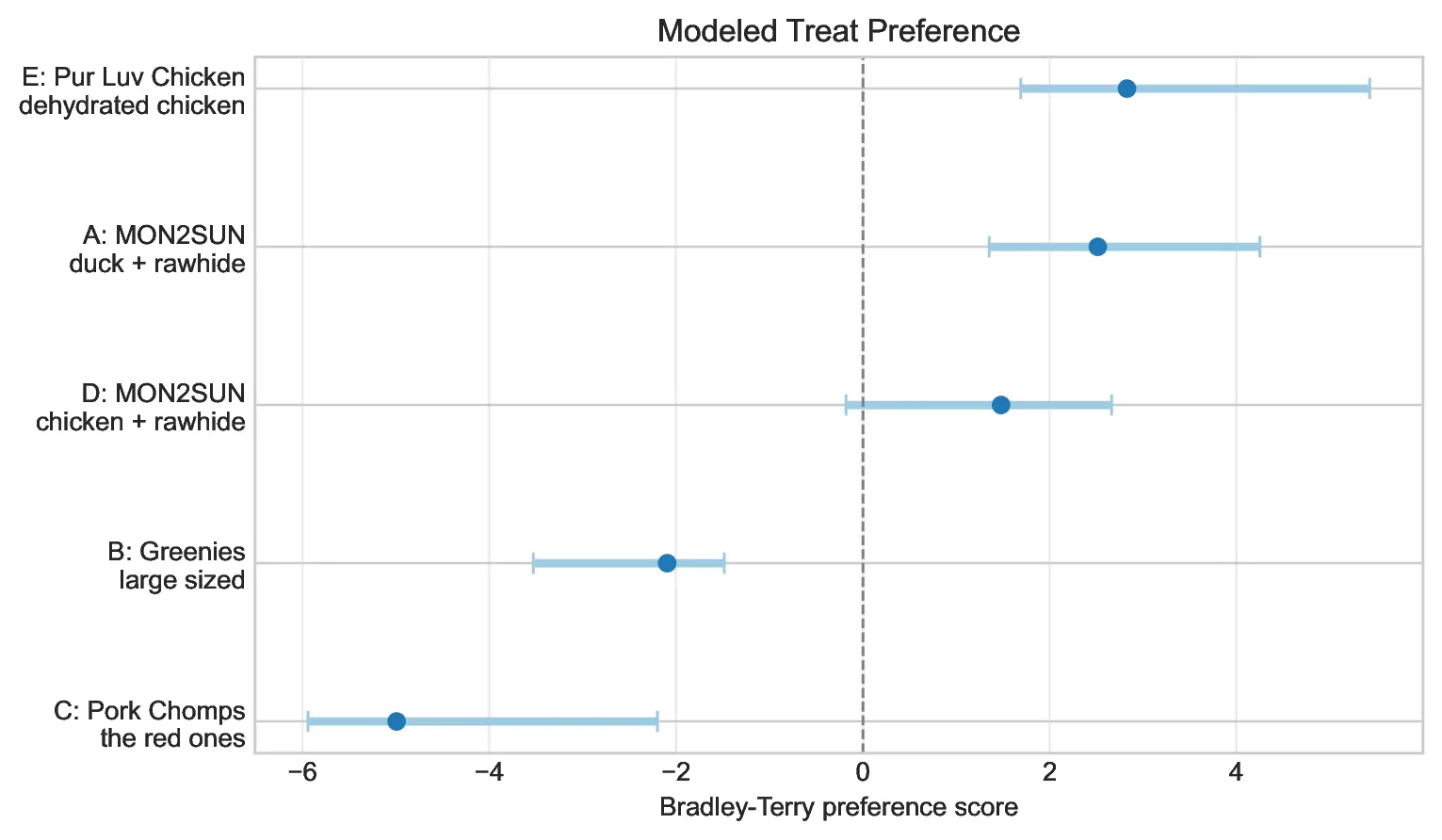
For the best treat, E is the current leader, with strong evidence that C and B are inferior. A remains a plausible challenger because the E/A head-to-head is only 3–2 and the model-implied probability of E beating A is 57.5%. D is viable but meaningfully behind both E and A. Further sampling should concentrate almost entirely on E vs A, with occasional A/D or E/D checks only if we care about validating the tier boundary.
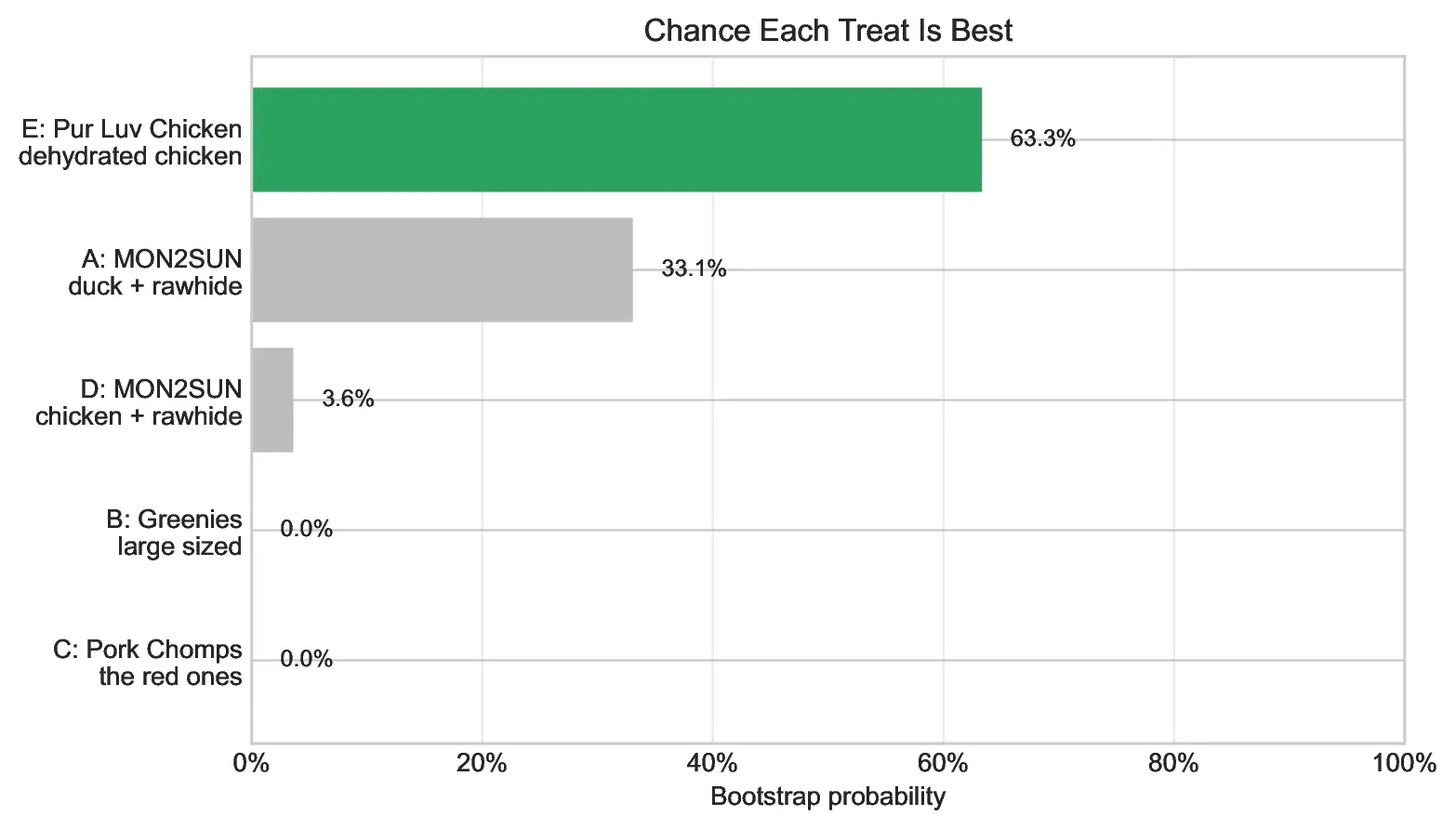
To estimate how settled the result was, I also ran a bootstrap experiment: repeatedly resampling the observed trials, fitting a new Bradley-Terry model each time, and recording which treat came out on top. Treat E finished first in 63% of bootstrap samples, Treat A finished first in 33%, and Treat D finished first in about 4%. Treats B and C were effectively out of contention.
So for now, Treat E wins: Pur Luv Chicken is Bebop’s current champion, which makes sense, because it’s dried chicken. However, the result is not completely settled. Treat A is close enough that the only honest next step is more E/A trials, which is convenient because Bebop remains highly committed to the scientific process.